Background screening system
In today's world, as large amounts of information are accessible online, “getting to know” someone is not a big challenge. The only things you need are the time to surf around, searching through all the abundance of available information, and the will to manually retrieve and analyze every bit of gathered information.
Due to large amounts of available information, conducting a background check for employment, renting or other purposes may be a tiresome task. Conducting a complete background screening may include police or criminal history record check, as well as credit card check – the sources not all which are easily accessible. In such cases, the use of an information retrieval system may prove to be of great use.
Basing our project on information retrieval techniques, which extract and organize unstructured information, as well as machine learning technologies to analyze the data, we built a custom solution tailored to the needs of our client. To build our background screening system, we chose to use the .NET Core stack as our development framework. Using the .NET Core stack to build our background screening system allowed us to take advantage of its powerful libraries and frameworks for information retrieval and machine learning, as well as its scalability and flexibility, which are crucial for handling large volumes of data.
Challenge
In the majority of cases when background screening is needed, speed of the process plays a crucial role. When done manually or by using outdated tools, the background checking process of a person or a particular applicant can take days, or even weeks, especially if there are many people involved and a thorough check is required.
There are many background screening services on the market, but none of them satisfied all the functional requirements for this project. We were tasked with building a new and custom solution, making use of Machine Learning and other advanced technologies to make the process faster and more accurate.
Requirements
The main goal of this project was to implement a scalable SaaS background check solution that covers all the relevant data sources from different social media (e.g. Facebook, Instagram, etc.) and different portals (Google, Bloomberg), or from more “official” data sources, such as criminal or civil records provided by courts or other government institutions. All this information needed to be analyzed and aggregated to provide a comprehensive background check of a person or a business.
Services that provide this type of data can be public or paid, and they provide information in a myriad of various formats – PDF, Word documents, JSON, HTML, etc. This mixture of unstructured, semi-structured and structured data makes it very difficult to collect, clean, parse, analyze, rate and categorize information. It usually means that a lot of manual work is required to give meaning to all that is collected.
Clients need comprehensive and complex reports on their subjects, and the existing products and services require a lot of copying and pasting between various data sources to produce deliverable documents. This is why there was a need to automate this process by using Natural Language Understanding techniques and Robotic Process Automation tools.
Solution
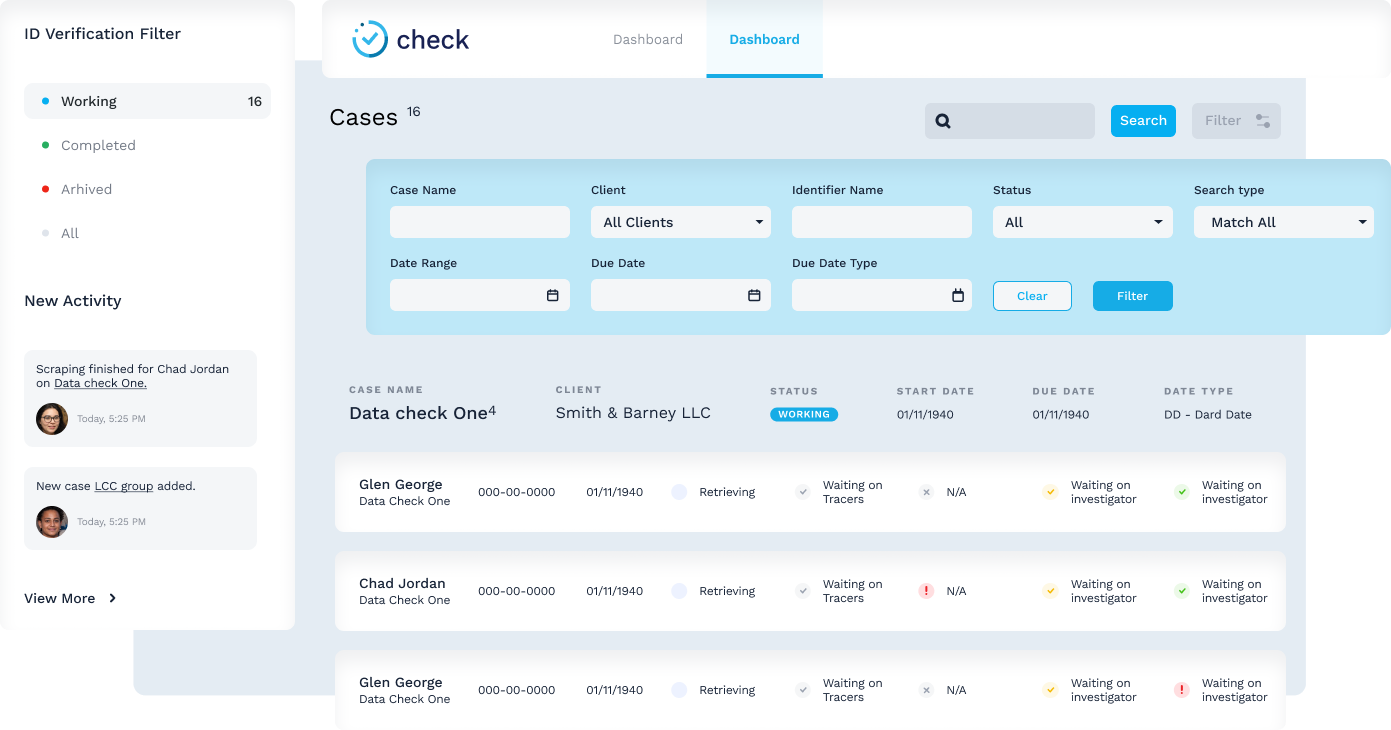
As a result of these requirements, an interactive and intuitive UI was developed to enable users to quickly comprehend the status of each subject and perform their day-to-day tasks in the most efficient manner.
Solution
We have implemented a complete multi-tenant background screening SaaS system that was able to handle hundreds of candidates per day. It automates labor-intensive tasks common to standard workflows, and results in a faster and more accurate screening process.
The coverage of the dataset is much wider compared to what it had been before. Any suspicious activity now comes into focus more readily and helps an organization assess all relevant risks that are a part of the hiring process.
Technical details
Our solution was developed using .NET Core stack.
The solution is designed using microservices architecture and is targeting cloud environments. It consists of multiple services, including:
- Web scraping service
- Messaging service
- Web API
- Investigator functionality
The system uses different information providers to collect data. Providers are categorized into different groups:
Id Verification
- Providers used to confirm search subject identity (SSN and DOB)
- Discover aliases
- Discover addresses
- Tracers, FACTS, LexComp
Sanctions Search
- Various derogatory information
- SAM.gov, Justice.org, sanctionssearch.ofac.treas.gov, brokercheck.finra.org etc.
Criminal/Civil search
- Various case records
- Federal/State Civil/Criminal
Real Estate
- Real estate history information
Bankruptcy
- Various credit reports
Degree Verification
- Confirmation of education
Professional License
- Licenses check
Derogatory News Search
- Law360
- Lexis Nexis
Our background check system is meant to be deployed in a cloud environment (Azure, Amazon...) and supports both vertical and horizontal scalability. It is utilizing cloud database and cloud storage solutions. Data at rest is secured on all levels.
Access to the system is restricted using IP address and user credentials. The system supports multi- factor authentication.
AWS Lambda (or an alternative "serverless" cloud service) can be used to execute service operations in a scalable manner. This is useful in asynchronous scenarios where providers don't return a response immediately. Scheduled jobs are executed to perform status checks in specified intervals. That way, we simply use resources when we need them instead of creating idle dedicated resources. Communication between service instances is done through MQTT protocol. RabbitMQ is used as a message broker.
To ensure easy maintenance, each service instance can be configured for a specific service provider. Multiple proxies are supported per each instance to avoid usage throttling limitations and IP restrictions imposed by source sites. A lot of work was invested into optimizing memory usage and proxy scheduling.
We have developed advanced techniques for handling Captcha challenges, while at the same time making sure that none of the target data sources are subject to overload or any other kind of unethical behavior. Multiple provider endpoints can be accessed in parallel via proxies, resulting in very fast data collection times. Operations that previously needed hours using standard web crawlers are compressed to minutes. Advanced system configuration allows administrators to configure the number of parallel tasks per domain, per proxy, and limit the total number of tasks – all depending on hardware configuration and other infrastructures used.
More details
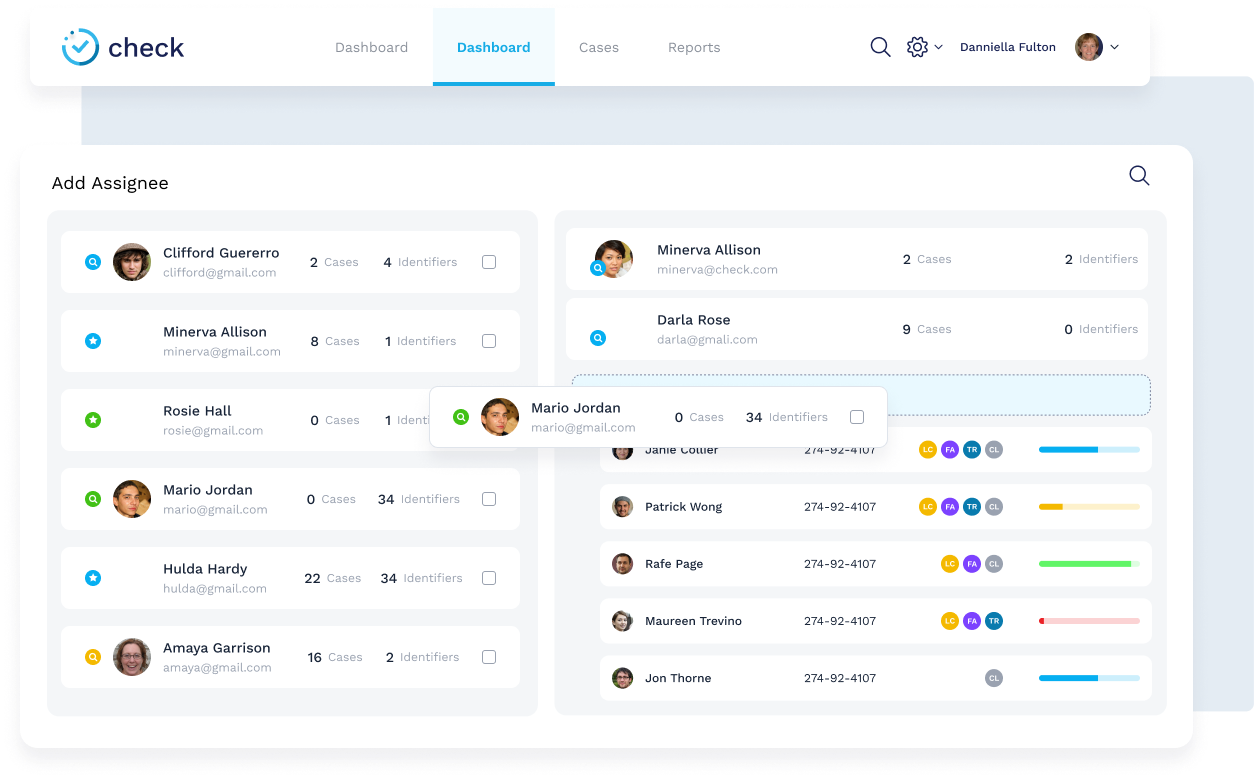
The scraping service is the main part of this solution. It is responsible for collecting and rating background check information.
Id Verification
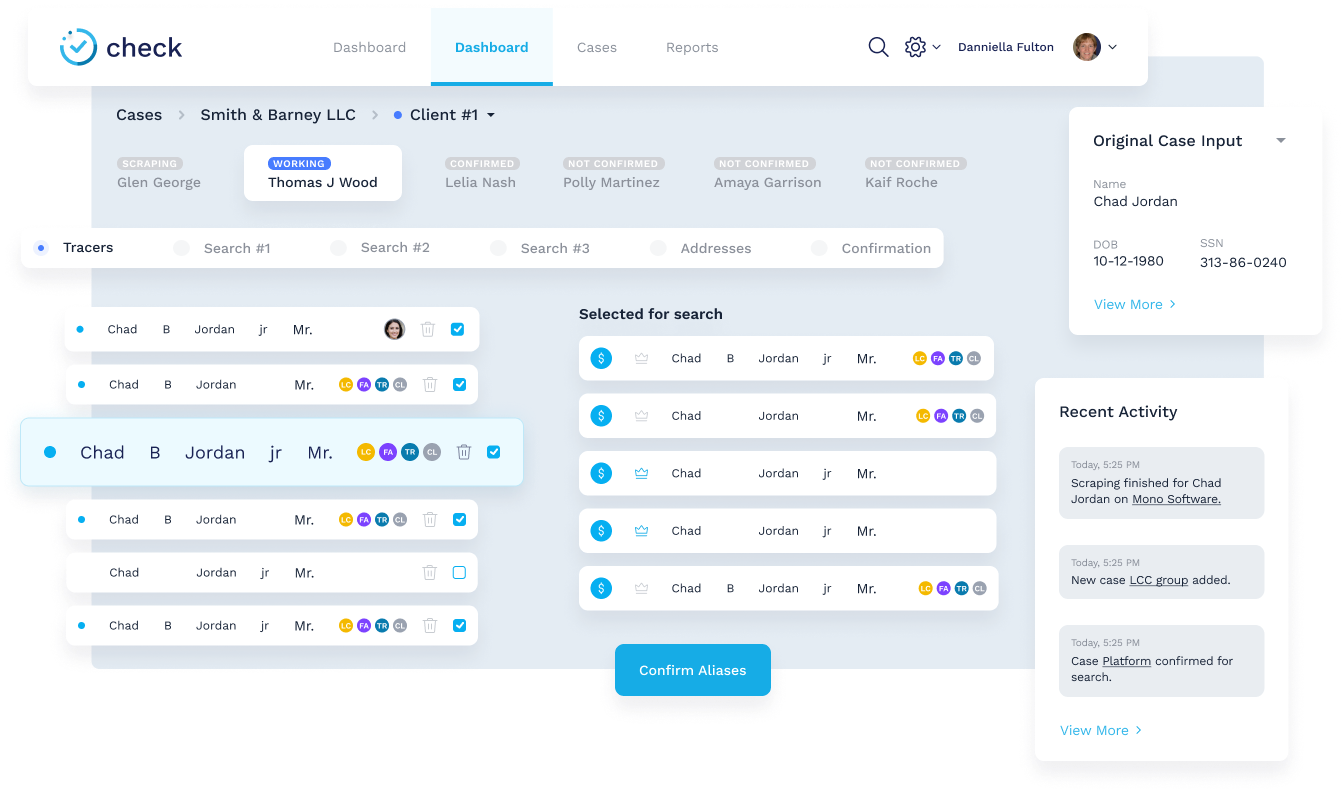
The background check process starts by a user submitting search subject information. The user submits all the information that is accessible to them – e.g. Name, SSN, DOB, known addresses and aliases, etc.
The system then contacts the data providers from the Id Verification category and confirms subject identity. It tries to find a unique match for the subject of the screening. If it succeeds and finds the match, it automatically selects that subject for later searches, collects aliases, addresses and other information that are re-used in later searches. In case there are multiple subjects returned and the system cannot determine subject identity with 100% confidence, user interaction is required.
After all the available data is collected, the user can select which of the collected data will be used in later searches (aliases, addresses etc.).
After all the searches are performed, the user can review the collected data, select the content that needs to be included in the final report, or alter automatic categorization. The system tracks all user actions and is capable of making more accurate future decisions depending on the previous decisions and user actions on them.
In some cases, collecting data can take a longer time (more than a few minutes). This mostly happens with data providers that hold credit and court records because some of them prepare search results manually. Nevertheless, the system intervenes in such cases as well. It performs periodical checks for status updates and notifies users when status changes.
Formatted Provider Responses
Some of the providers return formatted results. In such cases, the system is capable of parsing complete responses and extracting all data automatically. After completing these steps, it will include that information in the final report. Formatted responses can contain information about aliases, addresses (current and past), companies, business partners, court records, credit reports on various credit cards, fees etc. To determine the relevancy of all the formatted content, we have developed a custom rating algorithm.
Articles, blogs, social media...
Along with the formatted responses, our background check system collects information from sources that don't provide formatted responses, such as from articles, blog posts, social media posts and stories, as well as PDF, Word and other document types.
Instead of just collecting all of the unstructured content, the system uses advanced text filtering and content rating techniques to filter and rate the content, and, ultimately, to organize it based on relevancy.
We are using a combination of natural language processing services, such as Amazon Comprehend, and our custom solutions for named entity recognition. It is used to discover entities in downloaded content and calculate their relevance. This way, only relevant user information is presented to users, eliminating huge amounts of irrelevant information that is usually found when conducting manual and semi-automatic searches.
Conclusion
In conclusion, the background check system developed in this project is a comprehensive, scalable SaaS that utilizes advanced technologies such as machine learning and natural language understanding to quickly and accurately screen candidates. The system's microservices architecture and cloud-based design allows it to handle a large volume of candidates and automate labor-intensive tasks, while also dealing with structured and unstructured data, helping speed up and support the process of gathering necessary screening information.
Book a free consultation
Let us know what would you like to do. We will probably have some ideas on how to do it.